What does it do?
ScrapKit automates web scraping and converts the results in plain objects by using configuration objects called recipes.
Each recipe can be loaded as an object or as JSON file, and have the following structure:
{"url": "https://status.heroku.com/","attributes": {"apps": ".subnav__inner .ember-view:nth-child(1) > .status-summary__description","data": ".subnav__inner .ember-view:nth-child(2) > .status-summary__description","tools": ".subnav__inner .ember-view:nth-child(3) > .status-summary__description"}}
url: It defines the web page to scrape.attributes: Is an object that maps each attribute name with its corresponding CSS selector.
attributes can have a more complex structure to handle collections. For example:
{"url": "https://hpneo.dev/","attributes": {"posts": {"selector": ".post-item","children_attributes": {"title": "h2"}}}}
In this case attributes has a posts key, which will store the results of a collection, defined by a CSS selector and an object of children attributes.
children_attributes is an object that maps each attribute name with its corresponding CSS selector (similar to how attributes works in its simpler version).
Installation
Add this line to your application's Gemfile:
gem 'scrap_kit'And then execute:
$ bundleOr install it yourself as:
$ gem install scrap_kit
Usage
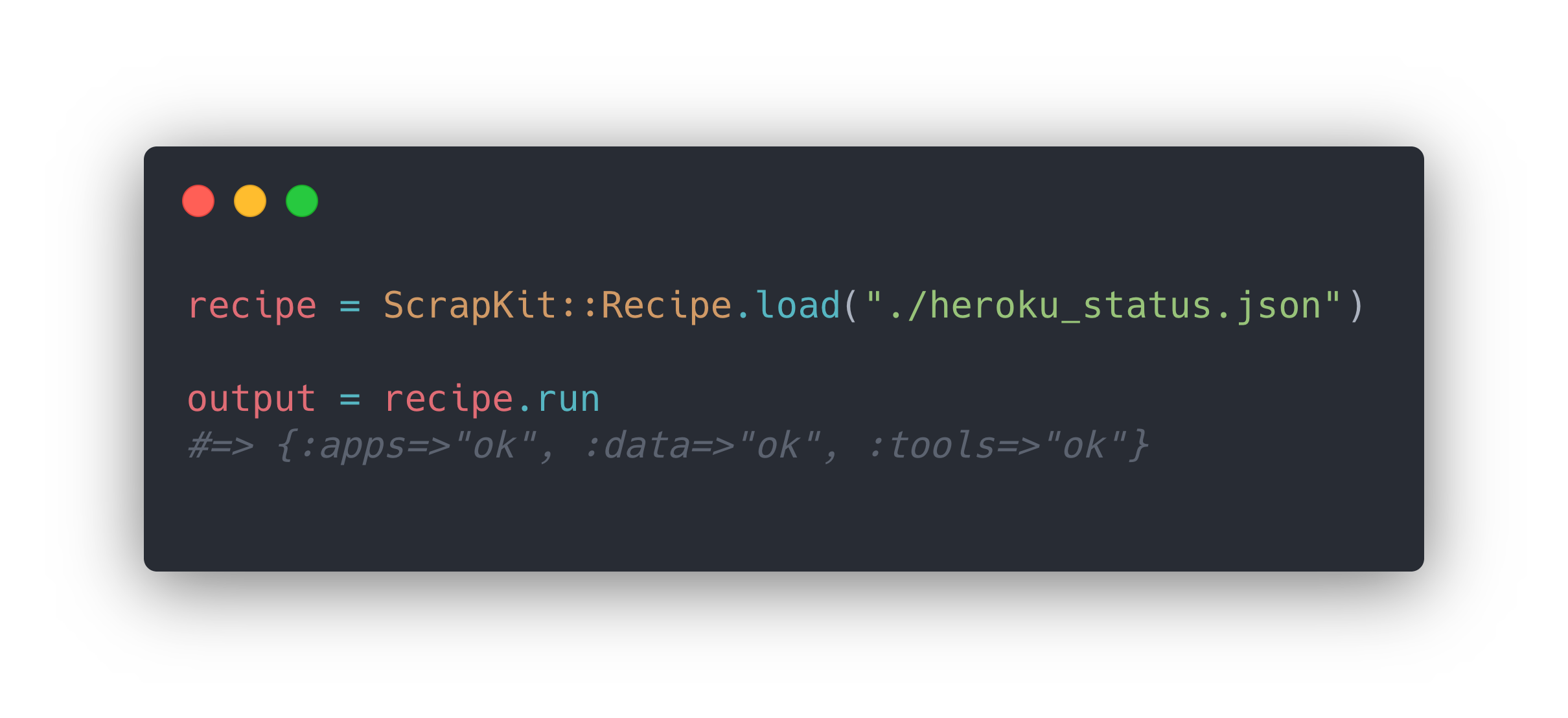
ScrapKit::Recipe.load can take an object with the recipe, or load a JSON file.
recipe = ScrapKit::Recipe.load(url: "https://status.heroku.com/",attributes: {apps: ".subnav__inner .status-summary:nth-child(1) > .status-summary__description",data: ".subnav__inner .status-summary:nth-child(2) > .status-summary__description",tools: ".subnav__inner .status-summary:nth-child(3) > .status-summary__description",})output = recipe.run#=> {:apps=>"ok", :data=>"ok", :tools=>"ok"}
For more complex structures it's recommended to store the recipe in a JSON file:
recipe = ScrapKit::Recipe.load("./spec/fixtures/file.json")output = recipe.run#=> {:posts=>[{:title=>"APIs de Internacionalización en JavaScript"}, {:title=>"Ejecutando comandos desde Ruby"}, {:title=>"Usando Higher-Order Components"}]}